영속성 컨텍스트 (Persistence Context)
🎬Intro
영속성 컨텍스트를 알아봅시다.
✅ 영속성
영속성 컨텍스트는 엔티티를 관리하는 일종의 저장소 입니다. 구체적으로 말하면, JPA가 관리하는 엔티티 객체들이 저장되고
상태가 관리되는 공간 입니다. 이 저장소는 주로 엔티티의 생명주기를 관리 합니다. 영속성 컨텍스트에 저장된 엔티티들은 트랜잭션 커밋 시점에 DB에 반영되게 됩니다.
✅ 엔티티
엔티티는 JPA에서 DB의 테이블 필드값과 매핑되는 객체를 말합니다.
✅ 영속성 컨텍스트의 기능
1차 캐시
영속성 컨텍스트는 엔티티를 1차 캐시에 저장하여, 동일한 트랜잭션 내에서 반복 조회 시 DB에 다시 접근하지 않고 캐시에서 데이터를 가져옵니다. 이는 성능을 향상시키는 데 중요한 역할을 합니다.
예를 들어, 어떤 엔티티를 find() 메서드로 조회하면, 영속성 컨텍스트는 먼저 1차 캐시를 확인합니다. 만약 1차 캐시에 해당 엔티티가 있으면, DB에 접근하지 않고 캐시에 있는 엔티티를 반환하는것이죠
동일성(Identity)
DB 레코드와 매핑된 자바 객체는 영속성 컨텍스트에서 단 하나의 객체로 관리됩니다. 즉, 동일한 DB 레코드를 조회하면, 새로운 객체를 생성하는것이 아니라 이미 영속성 컨텍스트에 존재하는 객체의 참조를 반환합니다.
변경 감지(Dirty Checking)
영속성 컨텍스트는 엔티티의 변경 사항을 자동으로 감지 합니다 예를 들어, 어떤 엔티티의 필드 값을 변경하면, 트랜잭션이 끝날 때 JPA가 변경된 내용을 데이터베이스에 자동으로 업데이트 합니다. 즉, 커밋 시점에 DB에 UPDATE 쿼리가 자동으로 날라가는것이죠
쓰기 지연
자바 객체의 상태가 변경되면, 영속성 컨텍스트는 이 변경 사항을 추적합니다. 하지만 이 변경 사항은 즉시 DB에 반영되지 않습니다. 대신, 영속성 컨텍스트는 변경된 자바 객체들을 쓰기 지연 SQL 저장소라는 곳에 쌓아둡니다.
그리고 트랜잭션이 끝나는 시점, 즉 commit이 호출될 때, 영속성 컨택스트는 이 저장소에 쌓여 있던 SQL 명령들을 한꺼번에 DB에 전송하여 반영합니다.**
📝 예제
그럼 이제 예를 통해 더 자세히 알아보겠습니다.
코드 구조
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
@Entity
@Table
@Data
@NoArgsConstructor
public class MyEntity {
@Id
@GeneratedValue(strategy = GenerationType.SEQUENCE)
private Long id;
private String name;
@Builder
private MyEntity(Long id, String name) {
this.id = id;
this.name = name;
}
}
@Repository
public interface MyEntityRepository extends JpaRepository<MyEntity, Long> {
}
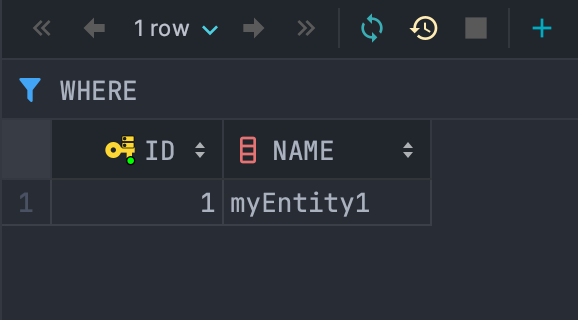
- 현재 DB에는 id가 1인 엔티티가 저장되어 있습니다.
MyEntity를 엔티티로 선언합니다.- id 생성 전략은 SEQUENCE로 되어있습니다.
SEQUENCE: jpa는 persist(save) 시점에 먼저 시퀀스에서 다음 값을 가져오는 SELECT 쿼리를 실행하고, 그 후 해당 값을 쓰기 지연 메커니즘에따라 커밋 시점에 INSERT 쿼리를 실행합니다. find의 경우 1차 캐시에 객체가 영속성 컨텍스트에 저장되어 있으면 SELECT 쿼리를 실행하지 않고 없으면 실행합니다. 이 후 변경값이 있으면 쓰기 지연에 따라 커밋 시점에 UPDATE 쿼리가 실행됩니다.IDENTITY: jpa는 persist(save) 시점에 SELECT 및 INSERT 쿼리를 즉시 실행합니다. 만약 DB에 동일한 id가 존재한다면 INSERT 쿼리는 실행되지않습니다. 따라서 IDENTITY는 save시점에 쓰기 지연을 지원하지 않습니다. find는 SEQUENCE와 동일하게 쓰기 지연을 지원합니다.
MyEntityRepository에JpaRepository를 상속하고@Repository를 붙여 빈으로 등록합니다.
예시 테스트 코드
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
@DataJpaTest
// 어플리케이션에서 설정한 DB를 그대로 사용, application.yml에 설정된 DB를 사용
@AutoConfigureTestDatabase(replace = AutoConfigureTestDatabase.Replace.NONE)
class PersistenceTest {
@Autowired
private MyEntityRepository repository;
@Autowired
private EntityManager em;
private MyEntity myEntity1;
private MyEntity myEntity2;
@BeforeEach
void setUpMyEntity() throws Exception {
myEntity1 = MyEntity.builder()
.id(1L)
.name("myEntity1")
.build();
myEntity2 = MyEntity.builder()
.id(null)
.name("myEntity2")
.build();
}
@DisplayName("영속성 컨텍스트 테스트")
@Test
void persistenceTest() throws Exception {
// given
// when
// case1. DB에 존재하는 id
System.out.println("====== SELECT O INSERT X ======");
MyEntity savedEntity1 = repository.save(myEntity1);
System.out.println("===============================");
// case2. DB에 존재하지 않는 id(null)
System.out.println("====== SELECT O INSERT O ======");
MyEntity savedEntity2 = repository.save(myEntity2);
System.out.println("쓰기 지연으로 INSERT 쿼리는 커밋 시점에 나감");
System.out.println("===============================");
// case3. 1차 캐시에 의해 셀렉문이 나가지 않는다. 동일성에 의해 myEntity1, myEntity2는 같은 객체다
System.out.println("====== SELECT X ======");
MyEntity myEntity1 = repository.findById(savedEntity1.getId()).orElse(null);
MyEntity myEntity2 = repository.findById(savedEntity1.getId()).orElse(null);
System.out.println("1차 캐시로 SELECT 쿼리는 나가지 않음");
System.out.println("======================");
// case4. 영속성 컨텍스트에 저장된 saveEntity1을 변경
System.out.println("====== SELECT X UPDATE O ======");
savedEntity1.setName("테스트2");
System.out.println("쓰기 지연으로 UPDATE 쿼리는 커밋 시점에 나감");
System.out.println("===============================");
System.out.println("======== DB 반영 ==========");
em.flush();
assertThat(myEntity1).isEqualTo(savedEntity1);
assertThat(myEntity2).isEqualTo(myEntity1);
}
}
case 1 (SELECT X INSERT O): myEntity1은 id 가 1이므로 이미 DB에 존재합니다. 따라서 persist 시점에 시퀀스 조회를 위해 SELECT 쿼리는 실행되지만, 커밋 시점에 INSERT 쿼리는 실행되지 않습니다.case 2 (SELECT X INSERT O): myEntity2는 ID가 null이므로 새로운 엔티티로 간주됩니다. 따라서 persist 시점에 시퀀스 조회를 위해 SELECT 쿼리가 실행되고, 커밋 시점에 INSERT 쿼리가 실행됩니다. (쓰기 지연)case 3 (SELECT X): savedEntity1은 persist 시점에 영속성 컨텍스트에 저장되었으므로 1차 캐시에 해당됩니다. 따라서 find시 추가적인 SELECT 쿼리가 실행되지 않습니다. 따라서 find가 반환 객체와 1차 캐시의 객체는 동일한 객체가 됩니다. (1차 캐시, 동일성)case 4 (SELECT X UPDATE O): 마찬가지로 savedEntity1은 1차 캐시이므로 추가적인 SELECT 쿼리가 실행되지 않으며, 변경이 발생했으므로 커밋 시점에 UPDATE 쿼리가 실행됩니다. (1차 캐시, 변경 감지, 쓰기 지연)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
====== SELECT O INSERT X ======
Hibernate:
select
me1_0.id,
me1_0.name
from
my_entity me1_0
where
me1_0.id=?
===============================
====== SELECT O INSERT O ======
Hibernate:
select
next value for my_entity_seq
쓰기 지연으로 INSERT 쿼리는 커밋 시점에 나감
===============================
====== SELECT X ======
1차 캐시로 SELECT 쿼리는 나가지 않음
======================
====== SELECT X UPDATE O ======
쓰기 지연으로 UPDATE 쿼리는 커밋 시점에 나감
===============================
======== DB 반영 ==========
Hibernate:
insert
into
my_entity
(name, id)
values
(?, ?)
Hibernate:
update
my_entity
set
name=?
where
id=?
- 쿼리 로그를 보면 1차 캐시, 쓰기 지연, 동일성, 변겨 감지 모두 잘 적용된것을 확인할 수 있습니다.
참고
@DataJpaTest는@Transactional을 감싸고 있습니다. 테스트 환경에서@Transactional이 붙어있을 경우 테스트 종료 시점에 자동으로 롤백이 됩니다. 따라서 em.flush()를 통해 강제로 DB 반영을 해야 쓰기 지연 쿼리 로그를 볼 수 있습니다.
✨Summary
- 영속성 컨텍스트는 JPA에서 엔티티의 생명주기를 관리하며, 1차 캐시, 동일성 보장, 변경 감지, 쓰기 지연 등의 기능을 통해 성능을 최적화합니다.
- 1차 캐시를 통해 동일 트랜잭션 내에서 동일한 엔티티 조회 시 DB에 재접근하지 않고 캐시에서 반환합니다.
- 변경 감지로 영속성 컨텍스트는 엔티티의 변경 사항을 추적하여, 트랜잭션 종료 시 DB에 자동으로 반영합니다.
- 쓰기 지연을 통해 변경된 엔티티는 커밋 시점에 한 번에 DB에 반영되어, 효율적인 데이터 처리가 가능합니다.
- 테스트 환경에서 @Transactional이 적용된 경우, 테스트 종료 시 자동 롤백되므로 flush()를 통해 쿼리 로그를 확인할 수 있습니다.